About CERMINE - Content ExtRactor and MINEr
CERMINE is a comprehensive open source system for extracting metadata and content from scientific articles in born-digital form. The system is able to process documents in PDF format and extracts:
- document's metadata, including title, authors, affiliations, abstract, keywords, journal name, volume and issue,
- parsed bibliographic references
- the structure of document's sections, section titles and paragraphs.
CERMINE is based on a modular workflow, whose architecture ensures that individual workflow steps can be maintained separately. As a result it is easy to perform evaluation, training, improve or replace one step implementation without changing other parts of the workflow. Most steps implementations utilize supervised and unsupervised machine-leaning techniques, which increases the maintainability of the system, as well as its ability to adapt to new document layouts.
REST service
CERMINE contains a REST service that allows for executing the extraction process by machines. REST service can be useful for digital libraries that do not have access to a built-in method for extracting metadata and content from documents. It can be accessed using cURL tool:
$ curl -X POST --data-binary @article.pdf \ --header "Content-Type: application/binary" -v \ http://cermine.ceon.pl/extract.do
How to cite CERMINE
Please cite the following paper:
Dominika Tkaczyk, Pawel Szostek, Mateusz Fedoryszak, Piotr Jan Dendek and Lukasz Bolikowski. CERMINE: automatic extraction of structured metadata from scientific literature. In International Journal on Document Analysis and Recognition, 2015, vol. 18, no. 4, pp. 317-335, doi: 10.1007/s10032-015-0249-8.
BibTeX:
@article{
author={Tkaczyk, Dominika and Szostek, Pawel and Fedoryszak, Mateusz and Dendek, Piotr Jan and Bolikowski, Lukasz},
title={CERMINE: automatic extraction of structured metadata from scientific literature},
journal={International Journal on Document Analysis and Recognition (IJDAR)},
issn={1433-2833},
publisher={Springer Berlin Heidelberg},
year={2015},
doi={10.1007/s10032-015-0249-8},
pages={317-335},
volume={18},
number={4},
url={http://dx.doi.org/10.1007/s10032-015-0249-8}
}
License
CERMINE is licensed under GNU Affero General Public License version 3.
Technical details
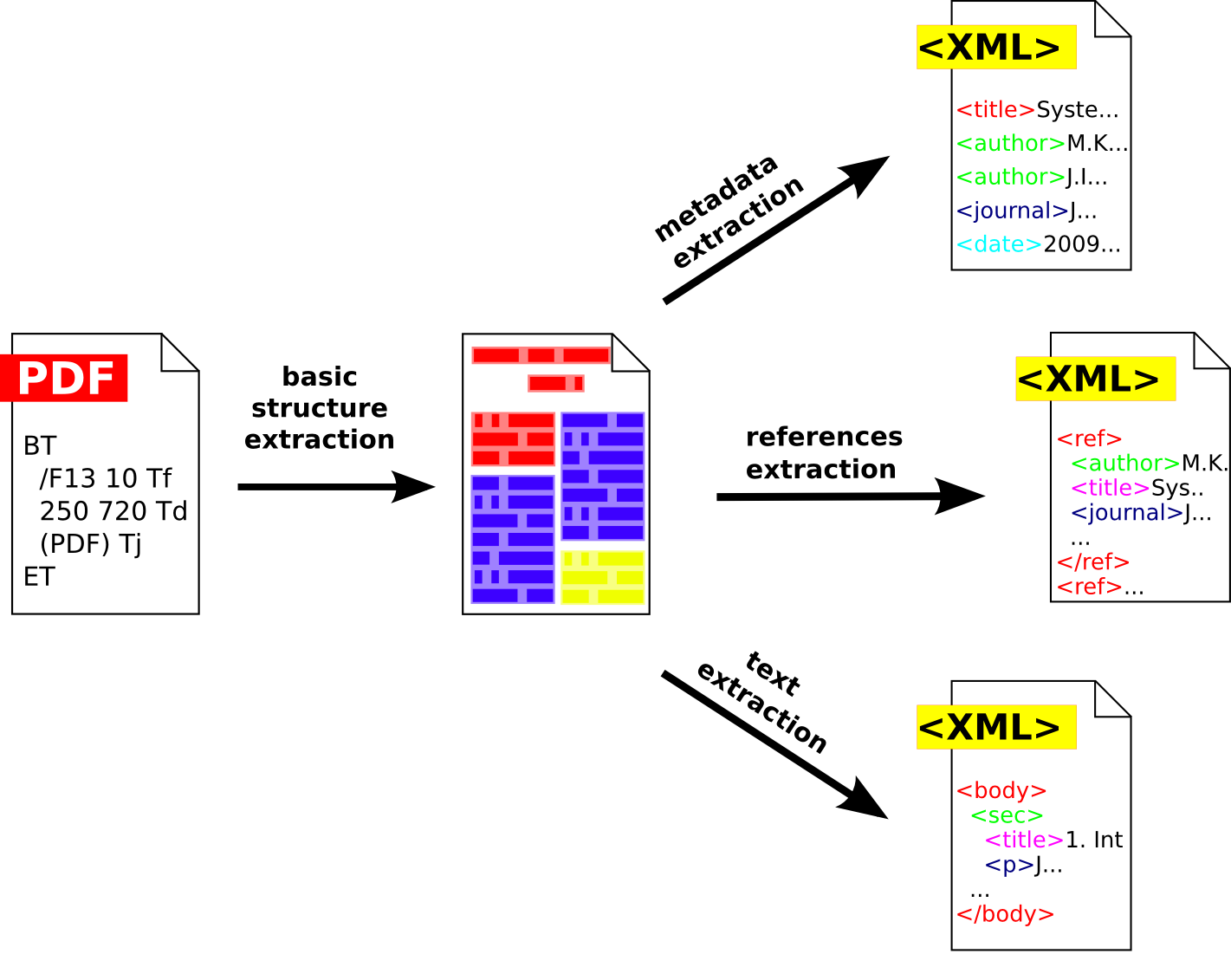
CERMINE workflow is composed of four main parts:
- Basic structure extraction takes a PDF file on the input and produces a geometric hierarchical structure representing the document. The structure is composed of pages, zones, lines, words and characters. The reading order of all elements is determined. Every zone is labelled with one of four general categories: METADATA, REFERENCES, BODY and OTHER.
- Metadata extraction part analyses parts of the geometric hierarchical structure labelled as METADATA and extracts a rich set of document's metadata from it.
- References extraction part analyses parts of the geometric hierarchical structure labelled as REFERENCES and the result is a list of document's parsed bibliographic references.
- Text extraction part analyses parts of the geometric hierarchical structure labelled as BODY and extracts document's body structure composed of sections, subsections and paragraphs.
CERMINE uses supervised and unsupervised machine-leaning techniques, such as Support Vector Machines, K-means clustering and Conditional Random Fields. Content classifiers are trained on GROTOAP2 dataset. More information about CERMINE can be found in the presentation.